Data Engineering - Azure Databricks and DuckDB
Github site: https://github.com/mcliston/azure_databricks_dataengineering
Project intro:
Being a bay area sports fan, I've always wondered how the teams I grew up with compared to dominant teams that came before like the 2010-2014 San Francisco Giants vs. the Yankee teams of the past and the 49ers vs. the 1970's Steelers.
Snooping around the Kaggle datasets, I came upon NBA database dataset and thought it would be a good opportunity to do a little data sleuthing to see how the recent Golden State Warriors success compared to the Kobe Bryant/Shaquille O'Neal Lakers...
Note
Since this is a data engineering section, topics will be for the most part data engineering centric. There will be a related Analysis/ML section to follow

Tools used:
- Azure Blob Storage
- Azure Databricks (Spark, Workflows)
- DuckDB (querying parquet files)
- Python v3.12
- Pandas
Note
The transformations of the data used are just some of the many more that are going to be done in follow-on posts.
Azure Blob Storage
Like AWS S3, Azure Blob storage can hold a variety of file types which can be accessed quickly from a number of different tools. I this project I chose to store the data in parquet files because of their versatility and ability to use different types of compression (ZSTD, snappy, gzip, etc.), and I wanted to how DuckDB would handle the Azure envrironment.
I setup Azure Key Vault (may be over kill but once its setup, it easy to work with) for authentication between Databricks notebooks and Blob storage.
Getting container names and container keys in a Databricks notebook looks like the following:
storage_account_name = dbutils.secrets.get(scope="key-vault-scope", key="storage-acct-name")
storage_account_key = dbutils.secrets.get(scope="key-vault-scope", key="storage-account-key")
sas_token = dbutils.secrets.get(scope="key-vault-scope", key="sastoken")
It's also essential to setup a secret scope for the vault (which is a parameter in the dbutils.secrets.get()). Microsoft instructions to do so are here.
Interacting with Blob Storage from a Databricks notebook
Along with the storage account name and keys, to interface with Blob storage within a Databricks notebook, I also had to install the adlfs library. How its used in a notebook is in the code snippet below:
from adlfs import AzureBlobFileSystem
abfs = AzureBlobFileSystem(account_name=storage_account_name, account_key=storage_account_key) ## name and key from previous code block
To browse the Blob filesystem you can run the following:
files = abfs.ls("<container-name>")
print(files)
Saving transformed parquet files back to Blob storage is done with the following:
file_path = f"az://<container-name>/output.parquet"
with abfs.open(file_path, 'wb') as f:
df.to_parquet(f)
## notice that these saves are assuming a Pandas DataFrame. At the time of writing this I could not save to parquet directly from a Spark DataFrame.
Working with DuckDB in Azure (Transformation Task #1)
Working with DuckDB in Azure was more or less like working with it in any other environment. It was pretty seamless and painless and fast (albeit not as fast as Spark). I know that DuckDB can run queries in parallel but not sure the details when put in an environment like Databricks (benchmarking and research to come).
If you're familar with DuckDB, you know that it's allure is writing SQL queries to almost any time of data file and how well it's been optimized.
Because this is a data engineering project, I decided to make a small transformations library to keep things in order here.
How that library is used in a Databricks notebook is below:
from nba_analysis_tools.query_tools import PerTeamExtract
warriors = PerTeamExtract('Warriors', 2014, 2019, abfs_obj=abfs)
warriors_df, warriors_team_picks_df = warriors.run()
lakers = PerTeamExtract('Lakers', 1999, 2002, abfs_obj=abfs)
lakers_df, lakers_team_picks_df = lakers.run()
# making a general query for Kobe Bryant and Shaquille O'Neal since they were not drafted by the Lakers but spent the majority of there careers on the Lakers
draft_cols = lakers_team_picks_df.columns
col_q_lst = ['a.'+ i for i in draft_cols]
table = 'draft_history'
q = f"""
SELECT {",".join(col_q_lst)} FROM read_parquet('abfs://data/{table}.parquet') AS a WHERE a.player_name = 'Kobe Bryant' OR a.player_name LIKE 'Shaq%'
"""
kobe_shaq = lakers._general_query(q)
lakers_team_picks_df = pd.concat([lakers_team_picks_df, kobe_shaq], axis=0)
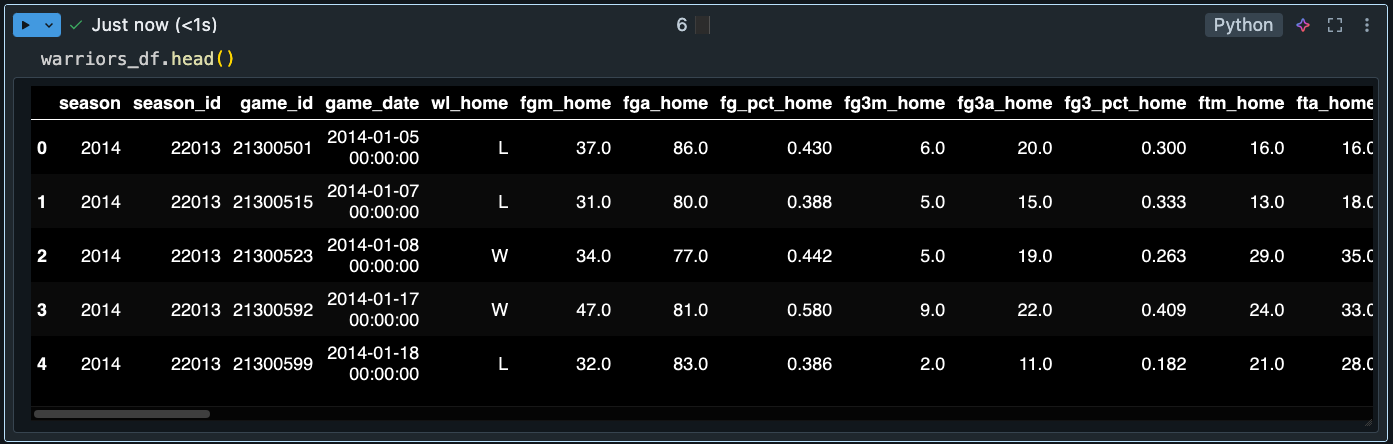
Desired output #1 - Simple join of 'game' and 'other_stats' table by game_id:
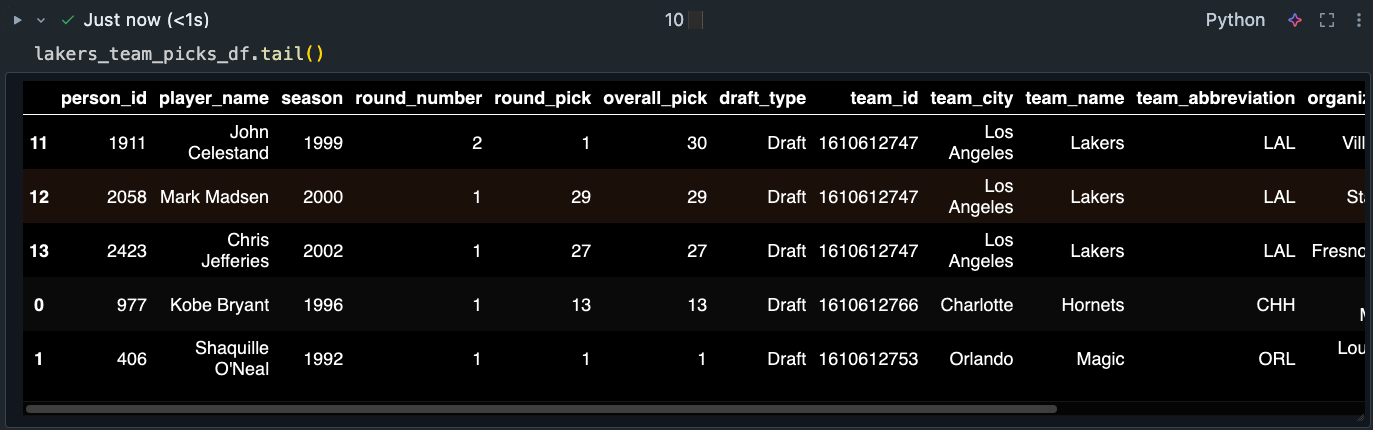
Desired output #2 - Extraction of all draft picks of a team 6 years before the start of their dominance up till the end of their run:
Interacting with Databricks (PySpark)
To setup an interface for PySpark to communicate with Blob storage, mount the storage container locally using the following:
dbutils.fs.mount(
source = "wasbs://<container-name>@<storage-account-name>.blob.core.windows.net",
mount_point = "/mnt/mydata",
extra_configs = {"fs.azure.account.key.<storage-account-name>.blob.core.windows.net": "<storage-account-key>"}
)
Note that the mount point name is arbitrary. This mount point will persist across compute sessions until you unmount with the following (within a Databricks Notebook):
dbutils.fs.unmount("/mnt/<my-container>")
List the contents of the mount point:
dbutils.fs.ls("/mnt/<my-container>")
List available mount points:
dbutils.fs.mounts()
Data transformations with PySpark DataFrames (Transformation Task #2)
PySpark DataFrames behave similarly to Pandas and Polars DataFrames but are optimized to use Spark clusters underneath the hood. Cleaning and transforming the data went as follows:
#importing
lakers_df = spark.read.parquet("/mnt/process2/lakers_df.parquet")
lakers_draft_df = spark.read.parquet("/mnt/process2/lakers_team_picks_df.parquet")
warriors_df = spark.read.parquet("/mnt/process2/warriors_df.parquet")
warriors_draft_df = spark.read.parquet("/mnt/process2/team_picks_df.parquet")
#using custom class "TeamStats"
warriors_team_stats = TeamStats(warriors_id,warriors_df, warriors_draft_df)
warriors_combined = warriors_team_stats.combine_stats()
lakers_team_stats = TeamStats(lakers_id,lakers_df, lakers_draft_df)
lakers_combined = lakers_team_stats.combine_stats()
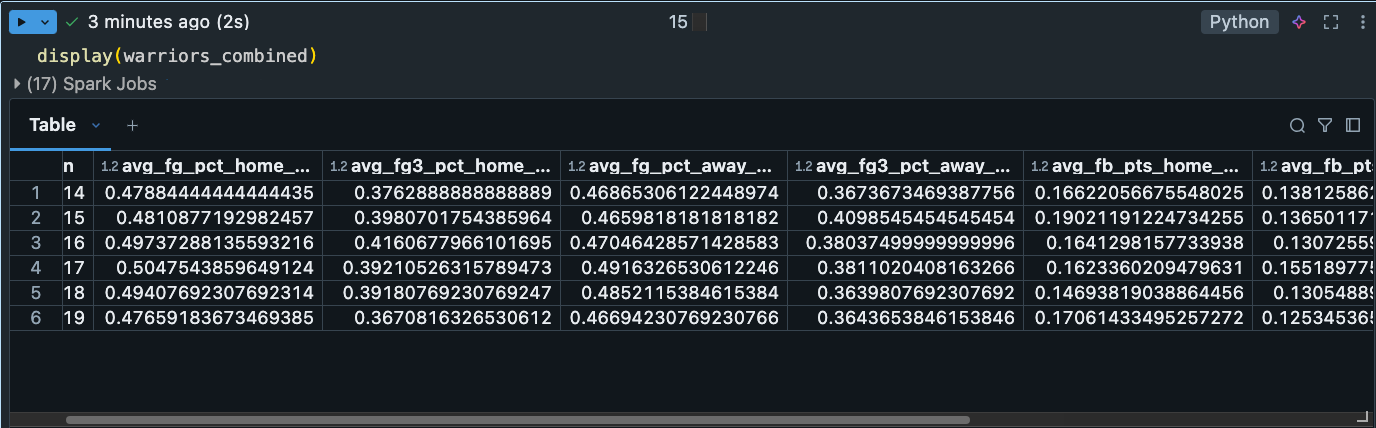
Tranformation 2 output #1 - A team's avg field goal percentage at home/away, avg fast-break ratio home/away, avg points-in-the-paint home/away, avg 3-pt percentage home/away:
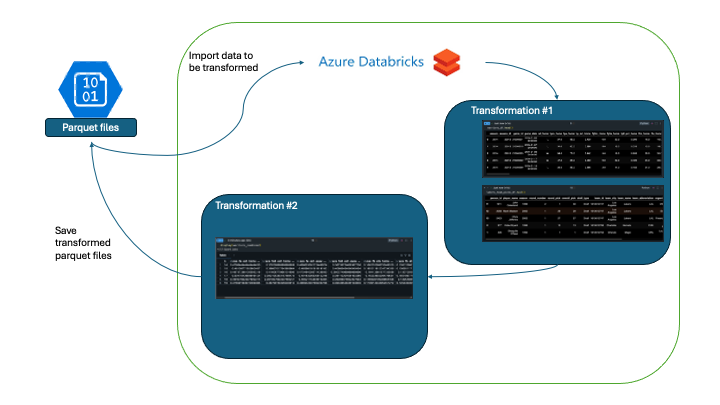
Orchestrating the Transformations - Databricks Workflows
With the transformation notebooks in place, it's time for executing/automating. With the many orchestration libraries available today (Dagster, Luigi, Prefect, Airflow, etc) its hard to make a decision because all do the job well and have great features. In this case, the built in Databricks Workflows are a great option because its integral to the nature of Databricks.
Setting up a workflow is just a couple of menu selection down from where notebooks are started:
Start workflow
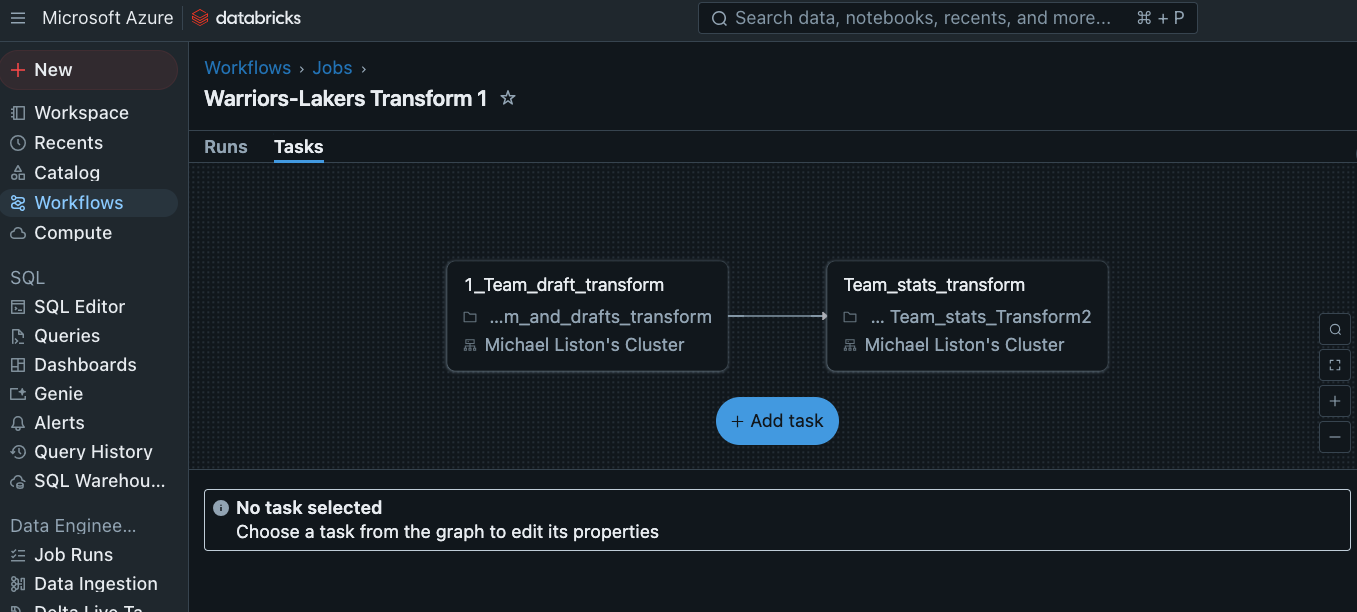
Assign notebooks to workflow
Post Conclusion
Starting the workflow saves the transformed parquet files back into a assigned results container in the Blob storage.
Next, I'll continue subsetting the NBA data set in search of the identities of these two basketball teams and what made them so successful. If I stay within the Azure/Databricks ecosystem I'll probably stay solely with PySpark since its a ton faster (DuckDB did really well regardless).